Subtitle generation with Subtitle Edit and Whisper
Images to Text
DVB transmissions often have graphic subtitles that many video playing devices cannot decode. Subtitle Edit can convert them to text (*.srt) files with various options of OCR processors, automatically and almost error free. Just record DVB including subtitles and let Subtitle Edit do its job, then multiplex the .srt files into your video file using e.g. MKVtoolNix. Note that Subtitle Edit has millions more features, just discover!
Speech to Text
Subtitle Edit also offers an audio to
subtile conversion based on Vosk, and also on Whisper.
Vosk is pretty fast (about 4x realtime on a good I5 CPU) but is not
perfect, good results only with a clearly spoken comment.
Whisper, based on openAI, is a lot slower on the CPU, but it also runs on a GPU.
With a decent GPU, like a GTX980 e.g., it can achieve up to 20x
realtime speed, using the "small" language model.
(status September 2023; this refers to Subtitle edit 4.01)
As mentioned above, Whisper can be used with Subtitle Edit. But the only option really working with the GPU so far appears to be Const-me:- Get the latest Version of Subtitle Edit, now 4.01.
- Select from the menu Video, Audio to Text , Whisper.
- In the window opening up, select Const-me.
- Download the Whisper model you want (small, medium, large...)
Most astonishing, here even the large model works on a 4GB GPU, and the conversion is very fast, 20 times real speed on a GTX980 with the small and still 4x with the large model. All models even run on a comparably tiny GTX730 GPU, the small model at about 2x real speed.
Subtitle Edit automatically corrects for Whisper timing errors. The latter option is not yet available separately in Subtitle Edit's batch processor (yet it doesn't currently correct for text sometimes appearing much too early and then for very long).There also is a necessary tweak for reliability:
The latest beta of Subtitle Edit has an "Advanced" key to enter additional parameters to const-me, which is badly needed:
Enter --max-context 1 here.
Without
it, many conversions may often go off rail,
suddenly repeating one subtitle line for several minutes and
subsequently failing to deliver good subtitles. You may experiment with
values above 1, but I always had some glitches with that. I guess it's the same issue that requires
--condition_on_previous_text False with the Python/GIT version of Whisper.
You may test const-me also via command prompt (see here how to get it), which displays text generated in real time, and also lists all parameters available. To do this, open a command prompt in C:\Users\(your user name)\AppData\Roaming\Subtitle Edit\Whisper\Const-me.
The quality gain for the medium and large models vs. the small one is not always obvious, but the large model knows a lot more things, which eliminates many spelling errors and sometimes produces results so good that it's almost uncanny. Sometimes it's getting weird, though, e.g., if a line saying "Copyright xxx" appears where there is not the slightest spoken text like that or any connection to xxx whatsoever... .
Maybe the larger model is better for rare languages, I would guess it is.Post processing Whisper's srt files:
From Subtitle Edit 4.03 on, there is a "break long lines" option directly in the Whisper start window, so an additional batch processing is no more necessary for this!
Subtitle Edit 4.05 beta now has a working version of Purfview's Faster Whisper. Well, it's actually not faster than const-me, takes 1.5 times as long with the small model and a lot more with the larger ones, as it loads more on the CPU when graphics memory gets short. But it does a pretty good job with the small model, the most care-free there is, so far. Keep advanced settings just at default. More on this may come when I did more jobs with it.
You may want to process srt files generated by Whisper alone, for two crucial purposes:
Splitting
long lines (Whisper makes many very long ones), and granting the right
character encoding by saving the files as UTF8 with BOM. This step is not necessary if we generated srt files from within Subtitle Edit, with the right options.
Subtitle Edit's batch function serves for this.The following images show some options to use for better line splitting, and some options useful for the batch processing.
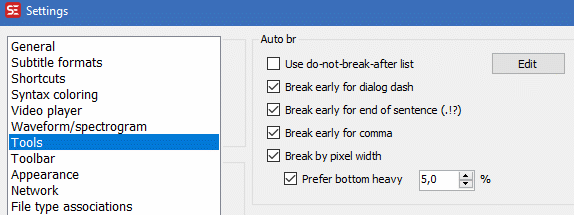
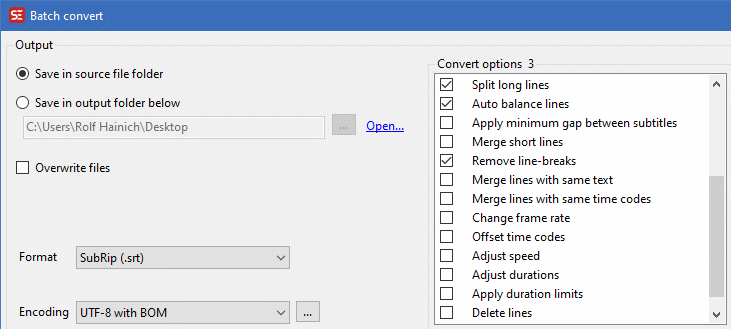
Note: Auto balance lines may fail quite often, so for reliability, maybe better leave it out.
You may also want to have the subtitles displayed in the preview window overlayed to the video, like when playing them back on TV. For this, just download mpv lib and then set your font size::
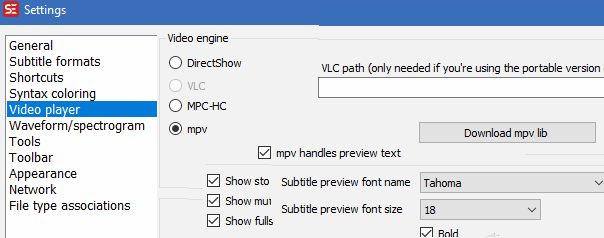
At last, we want to merge the subtitles with the videos.
Manually, this is done with MKVtoolNix. It's quite self explaining so I won't provide more to it here.
But
you may also want to use the batch processing tricks described here,
and in this case you can use the mkvmerge.exe program that comes with
MKVtoolNix and is found in it's program folder. Run it within a
command window and you'll get its help text describing the parameters
available.
I recommend adding a path entry for MVtoolNix' program folder so you can use the tools from anywhere in a command window.

Now you are in a command prompt window in the same folder.
Up to Windows 9, a command prompt could also be obtained by pressing Shift and right-clicking on a folder, then selecting 'open command prompt here'. In Windows 10/11, only Powershell is offered. There, an equivalent of a command prompt can be obtained in by selecting 'open Powershell window', and within the Powershell window, entering "cmd".
A genuine command prompt can also be opened from the Start Menu, ..Windows, ..System. (Right- click for options, such as as Run as Administrator). Then navigate to specific folders by cd <directory_name>. Entering cd.. gets you one level up.
A more convenient way may be to install OpenCommandPromptHere from 4dots-Software, letting you choose if you want the prompt in normal or admin mode, or FileMenuTools from Lopesoft, the latter one coming with lots more right-click tools.
If you want to build yourself a genuine command window option for any directory in windows 10/11 like it was in Windows 9, see here and here.
Or, in short (beware, only try this if you know what you're doing!):
- Start regedit, goto key HKEY_CLASSES_ROOT\Directory\shell\cmd
- Select permissions of the cmd key, extended, change the assignee to you username, then ok and ok,
- Then enter your username into the groups/usernames list, and allow it full access.
- Change the name of HideBasedOnVelocityId to ShowBasedOnVelocityId
- Perform the same steps with HKEY_CLASSES_ROOT\Directory\Background\shell\cmd
Sometimes it
may be convenient to do batch operations in the command window.
If you are subtitling
many files at once, it may especially be useful to merge subtitles into large numbers of video files automatically.
Here are some tricks for batch subtitle generation:
- Open a command prompt in the folder containing your files.
- Enter dir /b (or dir /b /s if you want to span subdirectories) in the window popping up, then copy all of the listing out of the command window (select the text, then type ctrl-C) then may paste this into some application window for further processing, typing ctrl-V.
- Now Excel or alike would come in handy: mark a column, then paste the dir listing by ctrl-V.
- Fill columns before and after with other parts of the commands you want to have executed, as well as some "s to allow for filenames with blanks in them.
- Then mark the entire field and copy by ctrl-C, paste it into an editor (the editor from Windows Accessories) window by ctrl-V, and save the text to some file. re-open the text, mark one of the many tabs (wide spaces) in the text and use replace-all to change them to nothing. Now we have all command lines ready.
- Select all , copy/paste them into a command window from the same directory where your files sit, and off you go!.
Why all that window copy/pasting? It avoids problems with special characters in file names.
These techniques also allow for making batch files processing through entire directory trees.
That's about all. The following paragraphs are left here for back reference only:
Whisper with Python and GIT (not recommended anymore)
Whisper can be used as a stand-alone app with Python and GIT. Yet this is my recommendation anymore, as Const-me that comes with Subtitle Edit works much faster and needs no cumbersome installetion. Yet if you want to waste some time, do this:
-
Install Nvidia CUDA 12, even if the current torch version is for 11.6,
that's no problem. Only if CUDA 12 says your hardware isn't fit, use
11.6.
- You need to sign up as a developer for the download CUDA, which is easily done.
- Do a custom install of CUDA, selecting only the runtime part, and the display driver (if your's not yet up to date).
- Download CUDNN and copy its files into a new folder, C:\Program Files\NVIDIA\CUDNN\v8.x\
- zLib is a data compression software library that is needed by CUDNN.
- Download and extract the zLib package.
- Copy the zlibwapi.dll from it into C:\Program Files\NVIDIA\CUDNN\v8.x\bin\
- Add a path entry C:\Program Files\NVIDIA\CUDNN\v8.x\bin
- How to add a path entry: right click on Computer, select Properties, Advanced Options, Environment Variables. There are two path strings you can edit, one for just your use an one for the system. Use system for hardware related things like CUDA. Click on the one intended, then "add new entry".
-
We also need ffmpeg command line version in order to extract audio from
various file formats:
- Download ffmpeg essential.
- Then create a folder C:\Program Files\ffmpeg\ and copy all files into it.
- Add a path entry C:\Program Files\ffmpeg\bin\
- Download GIT, 2.39 or newer, and
install it, all options default, but you may want to deselect adding to
context menu.
- Note: if you had GIT installed before, in particular without CUDA, then first uninstall it, and also delete the GIT folder in Program Files. Maybe you need to do so with Python as well.
- Add path entries C:\Program Files\Git\bin\git.exe and C:\Program Files\Git\cmd (the latter should already be there)
- Install Python 3.8 (or a version below 3.11), choose "add to environment variables" and "install pylauncher".
- Reboot in order to make sure the new path entries are loaded.
-
Get a command window in admin mode (Start menu - under
Windows, System) right click on it, run as admin) and
enter the following commands:
- pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
This will download approx. 2,4 GB !.
Note that it's crucial to get exactly this version, 116, others won't work !- python.exe -m pip install --upgrade pip
- pip install git+https://github.com/openai/whisper.git --use-pep517
(pep517 avoids some complaint about Wheel package not installed)
Now you may test, in a command window, supposed you have a file named test.wav
and you've opened a command window and navigated to the same directory (see hint on getting a window with a command prompt below):
- whisper "test.mkv" --model small --language English --device cuda
This will download the small language model, then generate text and subtitle files for test.mkv or whatever file you specified.
Some texts are difficult enough to get whisper in error loops; you will
notice this when some output lines are repeated many times instead of
generating the subsequent text. In this case, the option
- --condition_on_previous_text False
will help. It may also speed up the process in these cases, and it
reduces memory usage (e.g. only 2.4 GB of GPU memory instead of 3).
It's however not always better, may sometimes result in phrases from
one line being repeated in the next one.
Whisper packet sizes,
speed, memory usage
This is comparing an i5 CPU@4x4GHz an a GTX980 graphics card.
| model | file size MB | RAM GB | RAM GB | RAM GB | RAM GB | speed factor | speed factor |
| CPU | CPU c.o.p.t. | GPU | GPU c.o.p.t. | CPU | GPU | ||
| small | 472 | 1.8 | 1.8 | 2.5 | 3.4 | 0.45 | 5 |
| medium | 1492 | 4,7 | 4,5 | 6,5? | 8,5? | 0,18 | 2? |
| large | 3015 | 8,8 | 9,4 | 12? | 18? | 0.1 | 1? |
c.o.p.t. means --condition_on_previous_text True (the default setting)
Note that in addition to the above numbers, approx. 3 GB extra CPU memory may be necessary with Windows10, provided no other memory intensive apps are running.
With GPU, memory is absolutely critical, the process stops if even only a bit is missing. So most currently installed graphics cards may not be able to run the large models.
Note that the Const-me option in Subtitle edit is not only 4 times faster, but also allows to use even the large model efficiently with only 4 GB graphics RAM!
Copyright
(C) 2023; all
rights reserved. All
materials in these pages are presented for scientific evaluation
of video technologies only. They may not be copied from here and
used for entertainment or commercial activities of any kind.
We do not have any relation to and do not take any responsibility
for any software and links mentioned on this site. This website
does not contain any illegal software for download. If we, at
all, take up any 3rd party software here, it's with the explicit
permission of the author(s) and regarding all possible licensing
and copyright issues, as to our best knowledge. All external download
links go to the legal providers of the software concerned, as
to our best knowledge.
Any trademarks mentioned here are the property of their owners.
To our knowledge no trademark or patent infringement exists in
these documents; any such infringement would be purely unintentional.
If you have any questions or objections about materials posted
here, please e-mail us
immediately.
You may use the information presented herein at your own risk
and responsibility only. We do also not guarantee the correctness
of any information on this site or others and do not encourage
or recommend any use of it.
One further remark: These pages are covering only some aspects
of PC video and are not intended to be a complete overview or
an introduction for beginners.